Java의 리스트 클래스를 이해하자!
Java에서 대량의 자료를 추가/삭제하며 처리하기 위해서는 무엇을 사용해야 할까요?
연구실에서 Java를 한번쯤 공부해 본 사람이라면 보통 “Vector Class”라고 대답을 할 것입니다. 정답이죠. Vector Class는 대량의 자료를 가질수 있으며, 추가/삭제또한 자유롭게 처리가 가능합니다. 그럼 뭐가 문제라서 이런 글을 쓰는것일까요?
단순히 “처리되는가” 를 넘어서 “빠르게 처리할수 있는가” 를 생각해 본다면,
위에서의 대답 “Vector Class” 는 X에 가까운 답이라고 할 수 있기 때문입니다.
우선, Java에서 제공하는 “대용량 자료처리 개념” 은 여러가지 상위 인터페이스를 통해서 구현할 수 있습니다. (Collection, Iterator, Enumeration, Map등등) 각각 독특한 특징을 가지고 있습니다만, 이번에 다룰 내용은 Collection이하의 객체들이 되겠습니다.(나머지에 대해서도 다음 기회에 이야기 하도록 하겠습니다.)
Collection Interface는 “내부에 포함되는 요소는 순서를 가진다” 라는 특징을 가지고 있습니다. (이와 반대로 포함요소가 순서에 관계없이 저장되는녀석이 Map계열입니다.)
Collection을 계승(상속)해서 실제 구현된 객체들도 여럿 있습니다만, 그중에서도 대표적인 ArrayList, LinkedList, Vector 의 특징을 간단하게 설명하면 다음과 같습니다.
(HashSet, TreeSet같은 특이한 녀석들도 있습니다만… 일반적인 경우에 사용되는 녀석들은 아닌관계로, 설명은 다음기회로 넘기겠습니다…)
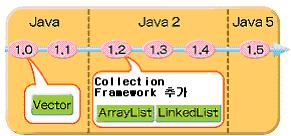
1. Vector
Java 1.0때 만들어져, 지금까지 유지되어온 클래스.
1.0버젼에서는 지금과 같은 List관련 객체들은 없었습니다.
이 버젼대에서 애용되었던 것이 Vector입니다.
Vector의 기본적인 동작은 다음에 설명할 ArrayList와 동일하기 때문에 넘어가기로 하고, 다른점만 설명하겠습니다.
Vector와 이후에 등장하는 List객체의 다른점은 “동기화(synchronize)”처리에 있습니다.
우선 “동기화” 라고 하는 개념에 대해서 간단하게 짚고 넘어가도록 하겠습니다.
두명의 학생이 하나의 컴퓨터를 사용하려고 합니다. 사용순서에 제한이 없기 때문에 서로 먼저 사용하려고 싸우게 되죠. 그러다보니 다음과 같은 상황이 발생합니다. 학생A가 워드로 “가나다라마바사…. ”를 적고 있는도중에 학생B가 키보드를 가로채서 “ABCDEFG…”를 입력해 버립니다. 두 학생은 하나의 자원(컴퓨터)를 공유하지만, 사용 순서에 대한 제한이 전혀 없기때문에 서로 상대방의 자료를 덮어써 버리는 일이 발생하게 되죠.
이것을 방지하기 위해서 자바에서는 synchronized 라는 키워드를 만들어 두었습니다. 이 키워드를 사용하면 공통된 자원에 접근하는것은 [반드시 한번에 하나!] 라는 조건이 붙게 되죠. 한 스레드(학생A)이 공유자원(컴퓨터)에 작업을 마치기 전 까지는 다른 스레드(학생B)가 공유자원(컴퓨터)에 접근을 할 수 없도록 약속해 버리는 것입니다. 이런 과정을 “동기화” 라고 합니다.
복수의 스레드로부터 데이터의 추가/삭제처리가 이루어졌을경우에도 내부의 데이터는 “안전”하게 한번에 한 스레드씩 처리가 이루어지도록 되어있다는 것이죠. 데이터의 안정성을 놓고 보았을때, 정말 좋은 일이 아닐수 없습니다.
… 만, 동기화가 문제시 되는 경우는 어디까지나 “공유자원”과 “복수사용자” 가 존재할때 성립되는 것입니다. 한개의 자원을 하나의 스레드가 사용하는 경우에도 동기화를 고려해서 처리를 하게 되면, 오히려 성능의 저하를 가져오게 되는 문제가 발생하죠. Vector의 경우는 “무조건 동기화” 이기 때문에 단일 스레드 처리에서는 앞으로 설명할 ArrayList나 LinkedList보다 성능이 떨어집니다. 자바 1.2 부터의 Vector의 주 사용목적은 1.0버젼과의 호환성이라고 생각하시는게 가장 좋을겁니다. 거의 쓸 일이 없다는 거죠. 혹시 동기화처리가 필요한 경우는 Vector를 이용하기 보다는 Collection. synchronizedCollection(Collection c)나synchronizedList, Map을 이용하는것이 성능상 바람직하겠습니다.
2. ArrayList
Java2 (1.2)에서 새로이 도입된 Collection의 구현객체입니다.
자료의 추가/삭제 등 기본적인 기능은 Vector와 동일하나, 내부적인 자동 동기화 기능이 삭제되어있죠. 때문에 다수의 스레드 환경에서 사용하기 위해서는 Vector설명에서 이야기했었던 Collection. synchronizedCollection(Collection c)를 이용해서 동기화 옵션을 설정해 주면 됩니다.
이름에서 알 수 있듯이, 내부적으로 자료를 Array(배열)구조로 가지고 있는 객체이죠. 데이터의 추가 / 삭제를 위해서 내부적 임시배열을 작성후 데이터를 복사하는 방법을 사용하고 있습니다.
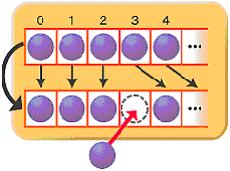
때문에, 대량의 자료를 추가 / 삭제하는 경우에 내부적인 처리량이 늘어나서 상당한 성능저하를 가져옵니다. (C에서 배열에 데이터 추가/삭제 해 보신분은 아시리라 믿습니다.)
대신, 각 데이터의 인덱스를 가지고 있기 때문에, 필요한 데이터에의 접근이 한번만에 가능하죠. (C에서 포인터를 이용해서 한방에 원하는 데이터에 접근하는것과 같습니다.)
보통, 많은 데이터를 한번에 몽땅 가져와서 여러번 참조해 쓸 때 최상의 성능을 나타내는 객체가 되겠습니다.
간단한 예로 정리를 하면,
물건을 사기위해서 5명의 사람이(손님 A,B,C,D,E) 의자에 앉아 차례를 기다리고 있는데,미리 순서를 예약해 둔 F라는 사람이 C의 앞에 불쑥 들어서서 자리를 비켜달라고 합니다. 예약을 했기때문에 C는 비켜야 하죠. 결국, C는 D의 자리로. D는 다시 E손님의 자리로 한칸씩 밀려나게 됩니다. 그럼 E는? 의자 옆에 빈 공간에 쭈그려 앉던지, 아니면 새로 의자를 요구해야 하겠죠.
이런 손님이 몇백명 있을경우에 도중에 한사람이 끼어들게 되면 뒤로 밀려야 할 사람의 수가 장난이 아니겠죠? 그런 처리를 내부적으로 해 주는것이 ArrayList객체가 되겠습니다.
3. LinkedList
연구실에서 C를 배우고 계시거나, 이미 C단계를 지나신 분들이 이해하기 쉬운 말로 바꾸면 “연결리스트” 입니다. 앞과 뒤의 구조체 주소를 가진 녀석들이 죽 ~ 나열된 모습. 그것이 바로 LinkedList객체의 실체입니다.
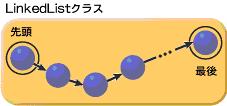
이녀석은 순서대로 늘어선 것이 아니라, 다음에 나올 자료의 위치정보만 가지고 있습니다. (앞과 뒤 모두 가진 객체도 있습니다.) 자기가 몇번째인지의 정보는 관심도 없죠.
Vector, ArrayList같이 인덱스정보를 가진 녀석들과의 차이점은 무엇일까요?
바로 추가 / 삭제의 용이함에 있습니다.
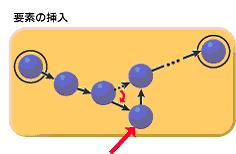
위의 그림에서 알 수 있듯이, 어떤 정보를 도중에 추가하기 위해서 다른 정보들을 뒤로 밀어내는 처리가 필요없습니다. 간단하게 글로 표현해 보면,
A-B-C-D 4명이 눈을 가린채, 서로 손을 잡고 있다고 하죠. 손을 잡기 전에 서로 다음에 오는 사람이 누군지만 확인을 한 상황입니다. 이 상태에서 E라는 사람을 B다음에 세우려면 어떻게 해야 할까요?
간단합니다. B의 손을C가 아닌 E를 잡도록 하고, E의 손이 C를 잡도록 살짝~ 도와만 주면 끝입니다. 요것이 LinkedList내부의 추가 처리입니다.(삭제는 역순임으로 설명은 생략)
데이터의 추가가 빈번하게 일어나는 자료를 처리하기 위한 객체라고 할 수 있습니다. 하지만, 데이터의 검색면에서는 어떨까요?
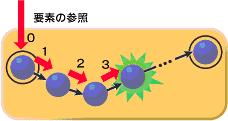
조금전의 예 – 손을 마주잡고있는 사람들 A-B-E-C-D 중에서 C를 찾아내서 물어볼것이 있습니다. 이 경우 어떻게 해야 하나요? ArrayList의 경우는 “몇번째 녀석이 C이다. “ 라는 목록을 내부적으로 가지고 있기 때문에 한번에 접근이 가능합니다. ... 만, LinkedList는 그런 목록을 가지고 있지 않기때문에, 최초의 정보A로부터 하나씩 검토를 해 나가야만 합니다.
A에게가서 C의 위치를 물어봐도 A는 B가 어디있는지 밖에 모르기때문에 B에게 가서 다시 C의 위치를 물어봐야 합니다. B는 E의 위치밖에 모르니 E에게 가서 또 물어봐야 하죠. 결국 E가 C의 위치를 알려주게 됩니다만… 확률적으로 n개의 데이터가 들어있을경우에 운이 좋으면 1번에, 운이 나쁜경우는 n번 움직여야만 원하는 데이터를 찾을 수 있게 됩니다. 데이터의 검색에는 그다지 적합하지 않은 녀석이죠.
(자료구조 같은 과목에서 검색패턴에 대한 좋은 이야기를 많이 들을 수 있을거에용~ ^^)
이야기를 정리하면,
- Vector – 구버젼 호환용. 그다지 사용되지 않음. 동기화 처리가 내부적으로 일어남으로 다른 객체보다 무거움.
- ArrayList – 배열의 복사에 의한 데이터 저장처리를 내부적으로 행하며, 각 데이터에 대한 인덱스를 가지고 있기때문에 검색이 매우 빠르다. 다만, 많은 데이터의 추가 / 삭제시에는 배열의 복사가 빈번하게 일어나, 성능이 떨어지는 단점이 있다.
- LinkedList – 다음 자료의 위치정보를 가지며, 내부적인 인덱스는 가지고 있지않다. 데이터의 추가 / 삭제는 위치정보의 수정만으로 가능하기 때문에 많은 정보의 추가 / 삭제처리가 필요할때 유용하다. 다만, 데이터가 많은 경우의 검색시 처음 자료로부터 순차적으로 찾아 나가야 하기 때문에 느려지는 단점이 있다.
아직 설명하지 못한 많은 저장 객체들이 존재합니다만…
일반적으로 사용되는 3가지에 대해서 간단하게 적어보았습니다.
왜 비슷한 기능을 가진 녀석들이 여러개 존재하는걸까~ 라고 생각하신다면 각각의 객체가 가지는 특징과 성능차에 대해서 공부해 보는것도 좋을거라고 생각합니다.
실제로 프로그램이라는건 “동작” 하는건 당연한거죠. 보다 좋은 “성능”을 낼 수 있느냐가 중요하다고 생각합니다.
0.01초의 성능차이도 동작하는 환경에 따라서는 생명선이 될 수도 있으니까요.
모두들 좀 더 재밌게~ 그리고 깊게 공부하시는데 조금이나마 보탬이 되었으면~
하는 마음에서 간단하게 적어보았습니다. ~ m(_ _)m